
本文首先介绍了并行计算的基本概念,然后简要阐述了R和并行计算的关系。之后作者从R用户的使用角度讨论了隐式和显示两种并行计算模式,并给出了相应的案例。隐式并行计算模式不仅提供了简单清晰的使用方法,而且很好的隐藏了并行计算的实现细节。因此用户可以专注于问题本身。显示并行计算模式则更加灵活多样,用户可以按照自己的实际问题来选择数据分解,内存管理和计算任务分配的方式。最后,作者探讨了现阶段R并行化的挑战以及未来的发展。
R与并行计算
统计之都的小伙伴们对R,SAS,SPSS, MATLAB之类的统计软件的使用定是轻车熟路了,但是对并行计算(又名高性能计算,分布式计算)等概念可能多少会感到有点陌生。应太云兄之邀,在此给大家介绍一些关于并行计算的基本概念以及在R中的使用。
什么是并行计算?
并行计算,准确地说应该包括高性能计算机和并行软件两个方面。在很长一段时间里,中国的高性能计算机处于世界领先水平。在最近一期的世界TOP500超级计算机排名中,中国的神威太湖之光列居榜首。 但是高性能计算机的应用领域却比较有限,主要集中在军事,航天航空等国防军工以及科研领域。对于多数个人,中小型企业来说高性能计算机还是阳春白雪。C” />C” />
 不过,近年来随着个人PC机,廉价机群,以及各种加速卡(NVIDIA GPU, Intel Xeon Phi, FPGA)的快速发展,现在个人电脑已经完全可以和过去的高性能计算机相媲美了。相比于计算机硬件的迅速发展,并行软件的发展多少有些滞后,试想你现在使用的哪些软件是支持并行化运算的呢?
不过,近年来随着个人PC机,廉价机群,以及各种加速卡(NVIDIA GPU, Intel Xeon Phi, FPGA)的快速发展,现在个人电脑已经完全可以和过去的高性能计算机相媲美了。相比于计算机硬件的迅速发展,并行软件的发展多少有些滞后,试想你现在使用的哪些软件是支持并行化运算的呢? C” />软件的并行化需要更多的研发支持,以及对大量串行算法和现有软件的并行化,这部分工作被称之为代码现代化(code modernization)。听起来相当高大上的工作,然而在实际中大量的错误修正(BUGFIX),底层数据结构重写,软件框架的更改,以及代码并行化之后带来的运行不确定性和跨平台等问题极大地增加了软件的开发维护成本和运行风险,这也使得这项工作在实际中并没有想象中的那么吸引人。
C” />软件的并行化需要更多的研发支持,以及对大量串行算法和现有软件的并行化,这部分工作被称之为代码现代化(code modernization)。听起来相当高大上的工作,然而在实际中大量的错误修正(BUGFIX),底层数据结构重写,软件框架的更改,以及代码并行化之后带来的运行不确定性和跨平台等问题极大地增加了软件的开发维护成本和运行风险,这也使得这项工作在实际中并没有想象中的那么吸引人。
R为什么需要并行计算?
那么言归正传,让我们回到R本身。R作为当前最流行的统计软件之一,具有非常多的优点,比如丰富的统计模型与数据处理工具,以及强大的可视化能力。但随着数据量的日渐增大,R的内存使用方式和计算模式限制了R处理大规模数据的能力。从内存角度来看,R采用的是内存计算模式(In-Memory),被处理的数据需要预取到主存(RAM)中。其优点是计算效率高、速度快,但缺点是这样一来能处理的问题规模就非常有限(小于RAM的大小)。另一方面,R的核心(R core)是一个单线程的程序。因此,在现代的多核处理器上,R无法有效地利用所有的计算内核。脑补一下,如果把R跑到具有260个计算核心的太湖之光CPU上,单线程的R程序最多只能利用到1/260的计算能力,而浪费了其他259/260的计算核心。
怎么破?并行计算!
并行计算技术正是为了在实际应用中解决单机内存容量和单核计算能力无法满足计算需求的问题而提出的。因此,并行计算技术将非常有力地扩充R的使用范围和场景。最新版本的R已经将parallel包设为了默认安装包。可见R核心开发组也对并行计算非常重视了。 C” />
C” />
R用户:如何使用并行计算?
从用户的使用方式来划分,R中的并行计算模式大致可以分为隐式和显示两种。下面我将用具体实例给大家做一个简单介绍。
隐式并行计算
隐式计算对用户隐藏了大部分细节,用户不需要知道具体数据分配方式 ,算法的实现或者底层的硬件资源分配。系统会根据当前的硬件资源来自动启动计算核心。显然,这种模式对于大多数用户来说是最喜闻乐见的。我们可以在完全不改变原有计算模式以及代码的情况下获得更高的性能。常见的隐式并行方式包括:
1、 使用并行计算库,如OpenBLAS,Intel MKL,NVIDIA cuBLAS
这类并行库通常是由硬件制造商提供并基于对应的硬件进行了深度优化,其性能远超R自带的BLAS库,所以建议在编译R的时候选择一个高性能库或者在运行时通过LD_PRELOAD来指定加载库。具体的编译和加载方法可以参见这篇博客的附录部分【1】。在下面左图中的矩阵计算比较实验中,并行库在16核的CPU上轻松超过R原有库百倍之多。在右图中,我们可以看到GPU的数学库对常见的一些分析算法也有相当显著的提速。C” /> 
2、使用R中的多线程函数
OpenMP是一种基于共享内存的多线程库,主要用于单节点上应用程序加速。最新的R在编译时就已经打开了OpenMP选项,这意味着一些计算可以在多线程的模式下运行。比如R中的dist函数就 是一个多线程实现的函数,通过设置线程数目来使用当前机器上的多个计算核心,下面我们用一个简单的例子来感受下并行计算的效率, GitHub上有完整代码【2】, 此代码需在Linux系统下运行。
#comparison of single thread and multiple threads run
for(i in 6:11) {
ORDER <- 2^i
m <- matrix(rnorm(ORDER*ORDER),ORDER,ORDER);
.Internal(setMaxNumMathThreads(1)); .Internal(setNumMathThreads(1)); res <- system.time(d <- dist(m))
print(res)
.Internal(setMaxNumMathThreads(20)); .Internal(setNumMathThreads(20)); res <- system.time(d <- dist(m))
print(res)
}
3、使用并行化包
在R高性能计算列表【3】中已经列出了一些现有的并行化包和工具。用户使用这些并行化包可以像使用其他所有R包一样快捷方便,始终专注于所处理的问题本身,而不必考虑太多关于并行化实现以及性能提升的问题。我们以H2O.ai【4】为例。 H2O后端使用Java实现多线程以及多机计算,前端的R接口简单清晰,用户只需要在加载包之后初始化H2O的线程数即可,后续的计算, 如GBM,GLM, DeepLearning算法,将会自动被分配到多个线程以及多个CPU上。详细函数可参见H2O文档【5】。
library(h2o)
h2o.init(nthreads = 4)
Connection successful!R is connected to the H2O cluster:
H2O cluster uptime: 1 hours 53 minutes
H2O cluster version: 3.8.3.3
H2O cluster name: H2O_started_from_R_patricz_ywj416
H2O cluster total nodes: 1
H2O cluster total memory: 1.55 GB
H2O cluster total cores: 4
H2O cluster allowed cores: 4
H2O cluster healthy: TRUE
H2O Connection ip: localhost
H2O Connection port: 54321
H2O Connection proxy: NA
R Version: R version 3.3.0 (2016-05-03)显示并行计算
显式计算则要求用户能够自己处理算例中数据划分,任务分配,计算以及最后的结果收集。因此,显式计算模式对用户的要求更高,用户不仅需要理解自己的算法,还需要对并行计算和硬件有一定的理解。值得庆幸的是,现有R中的并行计算框架,如parallel (snow,multicores),Rmpi和foreach等采用的是映射式并行模型(Mapping),使用方法简单清晰,极大地简化了编程复杂度。R用户只需要将现有程序转化为*apply或者for的循环形式之后,通过简单的API替换来实现并行计算。对于更为复杂的计算模式,用户可以通过重复映射收集(Map-Reduce)的过程来构造。 下面我们用一元二次方程求解问题来介绍如何利用*apply和foreach做并行化计算,完整的代码(ExplicitParallel.R)【6】可以在GitHuB上下载。首先,我们给出一个非向量化的一元二次方程求解函数,其中包括了对几种特殊情况的处理,如二次项系数为零,二次项以及一次项系数都为零或者开根号数为负。我们随机生成了3个大向量分别保存了方程的二次项,一次项和常数项系数。
下面我们用一元二次方程求解问题来介绍如何利用*apply和foreach做并行化计算,完整的代码(ExplicitParallel.R)【6】可以在GitHuB上下载。首先,我们给出一个非向量化的一元二次方程求解函数,其中包括了对几种特殊情况的处理,如二次项系数为零,二次项以及一次项系数都为零或者开根号数为负。我们随机生成了3个大向量分别保存了方程的二次项,一次项和常数项系数。
# Not vectorized function
solve.quad.eq <- function(a, b, c) {
# Not validate eqution: a and b are almost ZERO
if(abs(a) < 1e-8 && abs(b) < 1e-8) return(c(NA, NA) )
# Not quad equation
if(abs(a) < 1e-8 && abs(b) > 1e-8) return(c(-c/b, NA))
# No Solution
if(b*b - 4*a*c < 0) return(c(NA,NA))
# Return solutions
x.delta <- sqrt(b*b - 4*a*c)
x1 <- (-b + x.delta)/(2*a)
x2 <- (-b - x.delta)/(2*a)
return(c(x1, x2))
}
# Generate data
len <- 1e6
a <- runif(len, -10, 10)
a[sample(len, 100,replace=TRUE)] <- 0
b <- runif(len, -10, 10)
c <- runif(len, -10, 10)apply实现方式: 首先我们来看串行代码,下面的代码利用lapply函数将方程求解函数solve.quad.eq映射到每一组输入数据上,返回值保存到列表里。
# serial code
system.time(
res1.s <- lapply(1:len, FUN = function(x) { solve.quad.eq(a[x], b[x], c[x])})
)接下来,我们利用parallel包里的mcLapply (multicores)来并行化lapply中的计算。从API的接口来看,除了额外指定所需计算核心之外,mcLapply的使用方式和原有的lapply一致,这对用户来说额外的开发成本很低。mcLapply函数利用Linux下fork机制来创建多个当前R进程的副本并将输入索引分配到多个进程上,之后每个进程根据自己的索引进行计算,最后将其结果收集合并。在该例中我们指定了2个工作进程,一个进程计算1:(len/2), 另一个计算(len/2+1):len的数据,最后当mcLapply返回时将两部分结果合并到res1.p中。但是,由于multicores在底层使用了Linux进程创建机制,所以这个版本只能在Linux下执行。
# parallel
library(parallel)
# multicores on Linux
system.time(
res1.p <- mclapply(1:len, FUN = function(x) { solve.quad.eq(a[x], b[x], c[x])}, mc.cores = 2)
)对于非Linux用户来说,我们可以使用parallel包里的parLapply函数来实现并行化。parLapply函数支持Windows,Linux,Mac等不同的平台,可移植性更好,但是使用稍微复杂一点。在使用parLapply函数之前,我们首先需要建立一个计算组(cluster)。计算组是一个软件层次的概念,它指我们需要创建多少个R工作进程(parallel包会创建新的R工作进程,而非multicores里R父进程的副本)来进行计算,理论上计算组的大小并不受硬件环境的影响。比如说我们可以创建一个大小为1000的计算组,即有1000个R工作进程。 但在实际使用中,我们通常会使用和硬件计算资源相同数目的计算组,即每个R工作进程可以被单独映射到一个计算内核。如果计算群组的数目多于现有硬件资源,那么多个R工作进程将会共享现有的硬件资源。如下例我们先用detectCores确定当前电脑中的内核数目。值得注意的是detectCores的默认返回数目是超线程数目而非真正物理内核的数目。例如在我的笔记本电脑上有2个物理核心,而每个物理核心可以模拟两个超线程,所以detectCores()的返回值是4。 对于很多计算密集型任务来说,超线程对性能没有太大的帮助,所以使用logical=FALSE参数来获得实际物理内核的数目并创建一个相同数目的计算组。由于计算组中的进程是全新的R进程,所以在父进程中的数据和函数对子进程来说并不可见。因此,我们需要利用clusterExport把计算所需的数据和函数广播给计算组里的所有进程。最后parLapply将计算平均分配给计算组里的所有R进程,然后收集合并结果。
#Cluster on Windows
cores <- detectCores(logical = FALSE)
cl <- makeCluster(cores)
clusterExport(cl, c('solve.quad.eq', 'a', 'b', 'c'))
system.time(
res1.p <- parLapply(cl, 1:len, function(x) { solve.quad.eq(a[x], b[x], c[x]) })
)
stopCluster(cl)for实现方式: for循环的计算和*apply形式基本类似。在如下的串行实现中,我们提前创建了矩阵用来保存计算结果,for循环内部只需要逐一赋值即可。
# serial code
res2.s <- matrix(0, nrow=len, ncol = 2)
system.time(
for(i in 1:len) {
res2.s[i,] <- solve.quad.eq(a[i], b[i], c[i])
}
)对于for循环的并行化,我们可以使用foreach包里的%dopar% 操作将计算分配到多个计算核心。foreach包提供了一个软件层的数据映射方法,但不包括计算组的建立。因此,我们需要doParallel或者doMC包来创建计算组。计算组的创建和之前基本一样,当计算组建立之后,我们需要使用registerDoParallel来设定foreach后端的计算方式。这里我们从数据分配方式入手,我们希望给每个R工作进程分配一段连续的计算任务,即将1:len的数据均匀分配给每个R工作进程。假设我们有两个工作进程,那么进程1处理1到len/2的数据,进程2处理len/2+1到len的数据。所以在下面的程序中,我们将向量均匀分配到了计算组,每个进程计算chunk.size大小的联系任务。并且在进程内创建了矩阵来保存结果,最终foreach函数根据.combine指的的rbind函数将结果合并。
# foreach
library(foreach)
library(doParallel)
# Real physical cores in the computer
cores <- detectCores(logical=F)
cl <- makeCluster(cores)
registerDoParallel(cl, cores=cores)
# split data by ourselves
chunk.size <- len/cores
system.time(
res2.p <- foreach(i=1:cores, .combine='rbind') %dopar%
{ # local data for results
res <- matrix(0, nrow=chunk.size, ncol=2)
for(x in ((i-1)*chunk.size+1):(i*chunk.size)) {
res[x - (i-1)*chunk.size,] <- solve.quad.eq(a[x], b[x], c[x])
}
# return local results
res
}
)
stopImplicitCluster()
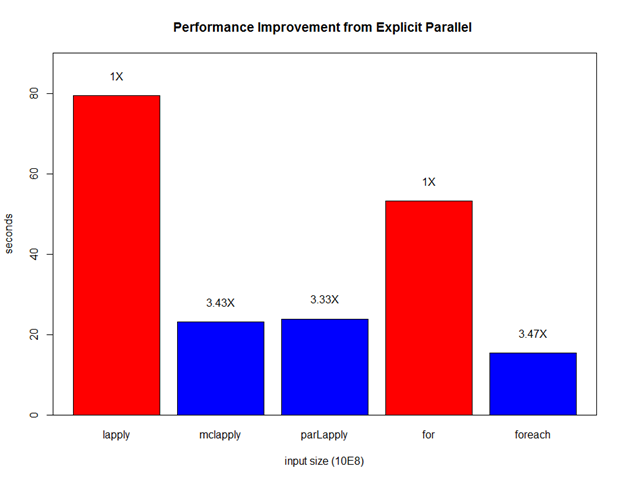
stopCluster(cl)最后,我们在Linux平台下使用4个线程进行测试,以上几个版本的并行实现均可达到3倍以上的加速比。 C” />
C” />
R并行化的挑战与展望
挑战:
在实际中,并行计算的问题并没有这么简单。要并行化R以及整个生态环境的挑战仍然巨大。
1、R是一个分散的,非商业化的软件
R并不是由一个紧凑的组织或者公司开发的,其大部分包是由用户自己开发的。这就意味着很难在软件架构和设计上来统一调整和部署。一些商业软件,比如Matlab,它的管理维护开发就很统一,架构的调整和局部重构相对要容易一些。通过几个版本的迭代,软件整体并行化的程度就要高很多。
2、R的底层设计仍是单线程,上层应用包依赖性很强
R最初是以单线程模式来设计的,意味着许多基础数据结构并不是线程安全的。所以,在上层并行算法实现时,很多数据结构需要重写或者调整,这也将破坏R本来的一些设计模式。另一方面,在R中,包的依赖性很强,我们假设使用B包,B包调用了A包。如果B包首先实现了多线程,但是在一段时间之后A包也做了并行化。那么这时候就很有可能出现混合并行的情况,程序就非常有可能出现各种奇怪的错误(BUG),性能也会大幅度降低。
展望:
未来 R并行化的主要模式是什么样的?以下纯属虚构,如果有雷同完全是巧合。
1、R将会更多的依赖于商业化以及研究机构提供的高性能组件
比如H2O,MXNet,Intel DAAL,这些包都很大程度的利用了并行性带来的效率提升,而且有相关人员长期更新和调优。从本质上来说,软件的发展是离不开人力和资金的投入的。
2、云计算平台
随着云计算的兴起,数据分析即服务(DAAS:Data Analyst as a Services)以及机器学习即服务(MLAS: machine learning as a services)的浪潮将会到来。 各大服务商从底层的硬件部署,数据库优化到上次的算法优化都提供了相应的并行化措施,比如微软近期推出了一系列R在云上的产品,更多信息请参见这篇文章。因此,未来更多的并行化工作将会对用户透明,R用户看到的还是原来的R,然而真正的计算已经分布到云端了。
本文转自 统计之都,原文链接:http://cos.name/2016/09/r-and-parallel-computing/作者简介赵鹏,世界知名IT企业性能分析师。在包括多核、分布式以及GPU通用计算方面具有丰富的研究和实践经验,善于帮助客户解决性能问题以及提供并行化方案。R语言爱好者,业余时间创建了ParallelR网站,www.parallelr.com,以此来分享R和并行计算相关内容。
参考资料【1】http://www.parallelr.com/r-hpac-benchmark-analysis/【2】https://github.com/PatricZhao/ParallelR/blob/master/PP_for_COS/ImplicitParallel_MT.R【3】https://cran.r-project.org/web/views/HighPerformanceComputing.html【4】http://www.h2o.ai/【5】http://docs.h2o.ai/h2o/latest-stable/h2o-docs/booklets/RBooklet.pdf【6】https://github.com/PatricZhao/ParallelR/blob/master/PP_for_COS/ExplicitParallel.R
本文采用「CC BY-SA 4.0 CN」协议转载自互联网、仅供学习交流,内容版权归原作者所有,如涉作品、版权和其他问题请给「我们」留言处理。


{kind=link}
{kind=link}
{kind=link}
{kind=link}